Frontier models are getting better at computer use, but they remain too slow and too expensive to use within creative software. Designing a movie poster in Photoshop can take hundreds of turns, and every step through a frontier API adds latency and cost. We wanted to see if a fine-tuned lower-cost model could do the same work faster and cheaper.
In this post, we show that a simple training recipe can fine-tune Qwen 3.6 27B to match Sonnet 4.6 and approach GPT-5.4 on basic photo-editing tasks. We post-trained the base model on Tinker: first with SFT on frontier trajectories, then with RL in PhotopeaBench, a new internal eval and environment. Our fine-tuned model reaches 96% of GPT-5.4's quality at two-thirds the cost, and slightly exceeds Sonnet 4.6 in performance for about 4x cheaper.
PhotopeaBench
PhotopeaBench is a benchmark and reinforcement learning environment for basic tool use and composition in photo-editing software.
We originally designed the benchmark around Adobe Photoshop, but meaningful RL iteration requires hundreds of parallel environments running full desktop GUIs and each would need its own Creative Cloud license at roughly $30/month. We switched to Photopea, a free browser-based Photoshop clone, which runs in a sandboxed browser with no licensing constraints.

PhotopeaBench is designed to evaluate and train computer use agents. The agent only has access to basic computer-use primitives: click, drag, type, key combos, scroll, and screenshot. There are no Photopea-specific tools, so the model has to learn the UI from pixels. Each environment runs as an isolated browser sandbox via Kernel, so hundreds run in parallel without desktop VMs. The system includes a harness for running rollouts, scoring outputs, and comparing models across task categories.
Each task consists of an instruction, a rubric, and a grading script that uses Gemini 3.0 Flash to score the rendered output against the rubric. This exploits the generator-verifier gap commonly referred to in reinforcement learning research: producing a correct edit requires long horizon tool use and precise visual grounding, while verifying whether the output matches a rubric is a much easier vision task that a smaller, cheaper model handles reliably.
We evaluated a range of frontier and open-weight baselines on PhotopeaBench to see how state-of-the-art models perform across a wide range of photo-editing capabilities.
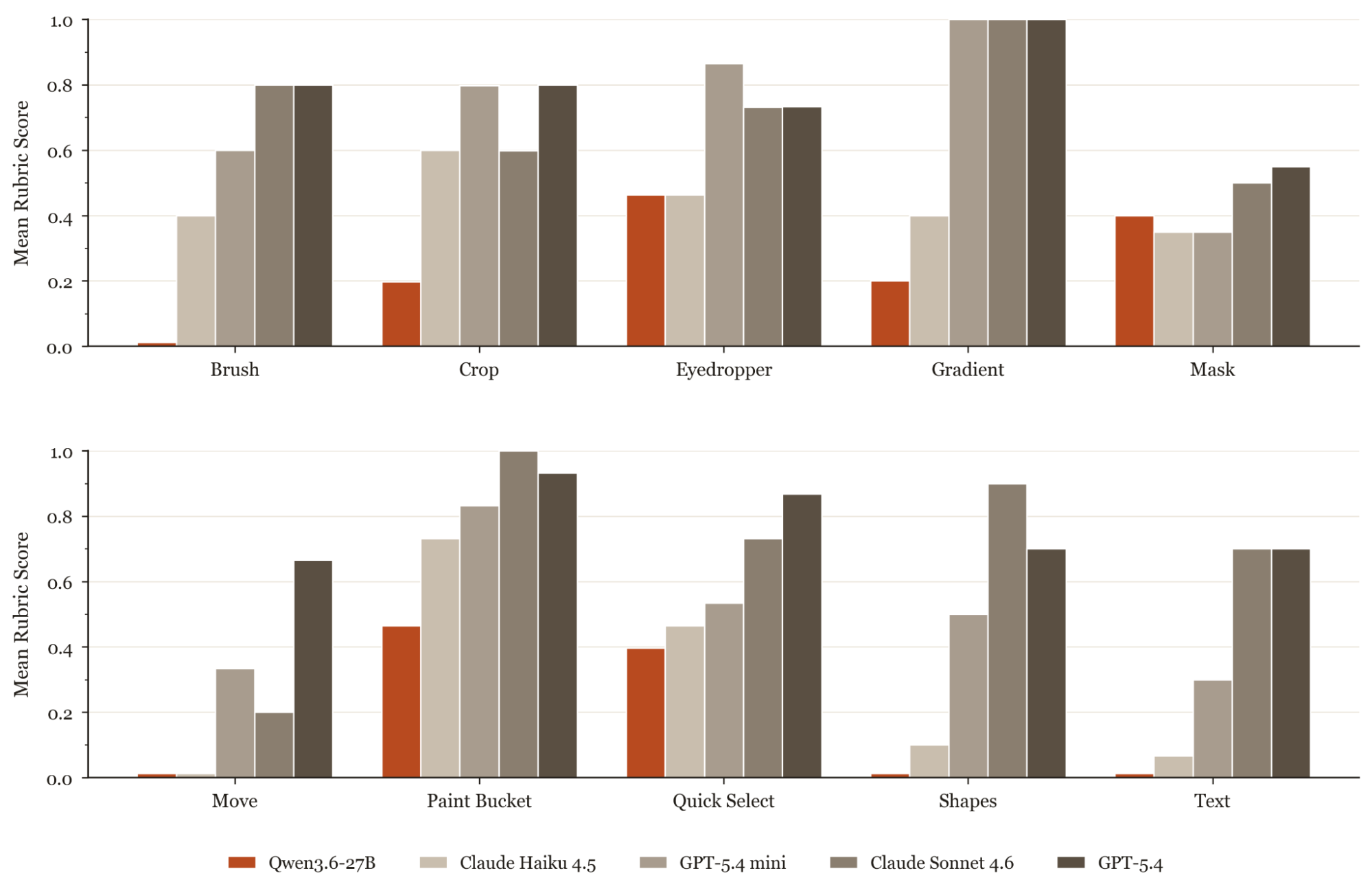
Sonnet 4.6 leads on long horizon tasks, with GPT-5.4 a close second. Open-weight models from the Qwen family perform poorly across the board. Our analysis of the trajectories shows that these models struggle with both computer use tools and visual grounding.
Training Recipe
Our recipe has two stages: supervised fine tuning on frontier model trajectories, followed by reinforcement learning on PhotopeaBench. We apply it to Qwen 3.6 27B, which balances capability, cost, and decoding speed according to our benchmarks.
Supervised Finetuning (SFT). We started by collecting roughly 1,000 trajectories from GPT-5.4 and Sonnet 4.6 on a synthetic version of PhotopeaBench. We graded each trajectory by the rubric and filtered by score, task completion, and trajectory length. After balancing across task categories, we were left with roughly 500 trajectories. Using two teacher models rather than one produced more diverse action sequences: Sonnet 4.6 was stronger on long-horizon tasks, while GPT-5.4 was more effective at using the batch tool to issue multiple actions at once.
The purpose of SFT is not to produce a competent model but to put the policy in the right neighborhood, so that RL has something to hill-climb from. We found that without an SFT mid-training step for base models, the pass@K for RL was too low for models to meaningfully learn. We trained with a next-token prediction objective on the action tokens only, masking screenshot tokens from the loss. We swept LoRA rank and learning rate; rank 32 with learning rate 5e-4 worked best, and higher ranks overfit on our small dataset.
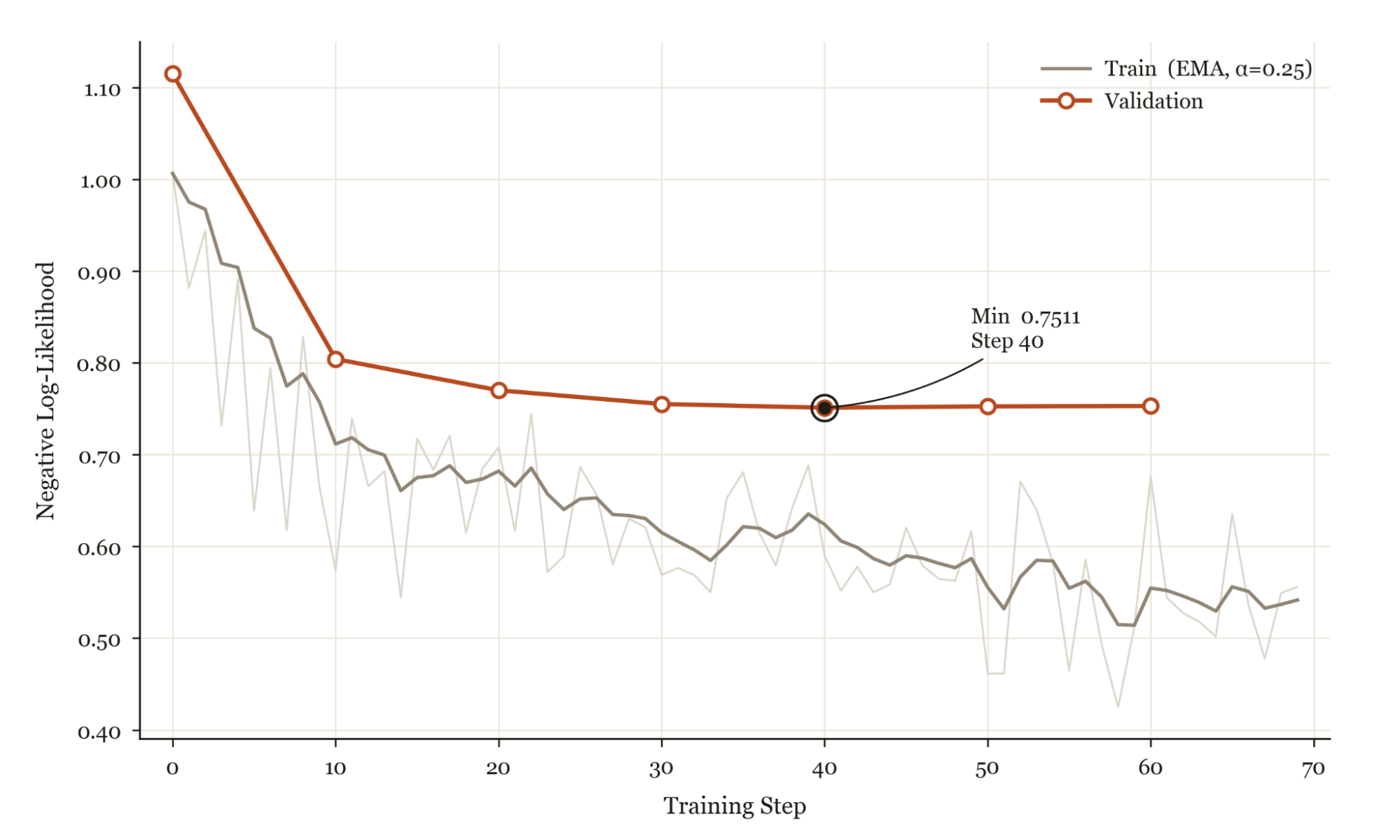
SFT alone brings Qwen 3.6 27B from 21% to 42% on PhotopeaBench, demonstrating the extraordinary ability of these models to learn from very few examples on downstream, narrow tasks.
We also explored training an inverse dynamics model on Photopea screen recordings from YouTube, following the approach in Standard Intelligence's FDM-1. The idea was attractive: YouTube has vastly more Photopea footage than we could generate synthetically, and IDM labeling would let us train on all of it. In practice, trajectories from frontier models carried much higher signal, since they include reasoning traces and follow instructions by default. We defer IDM-based training to future work.
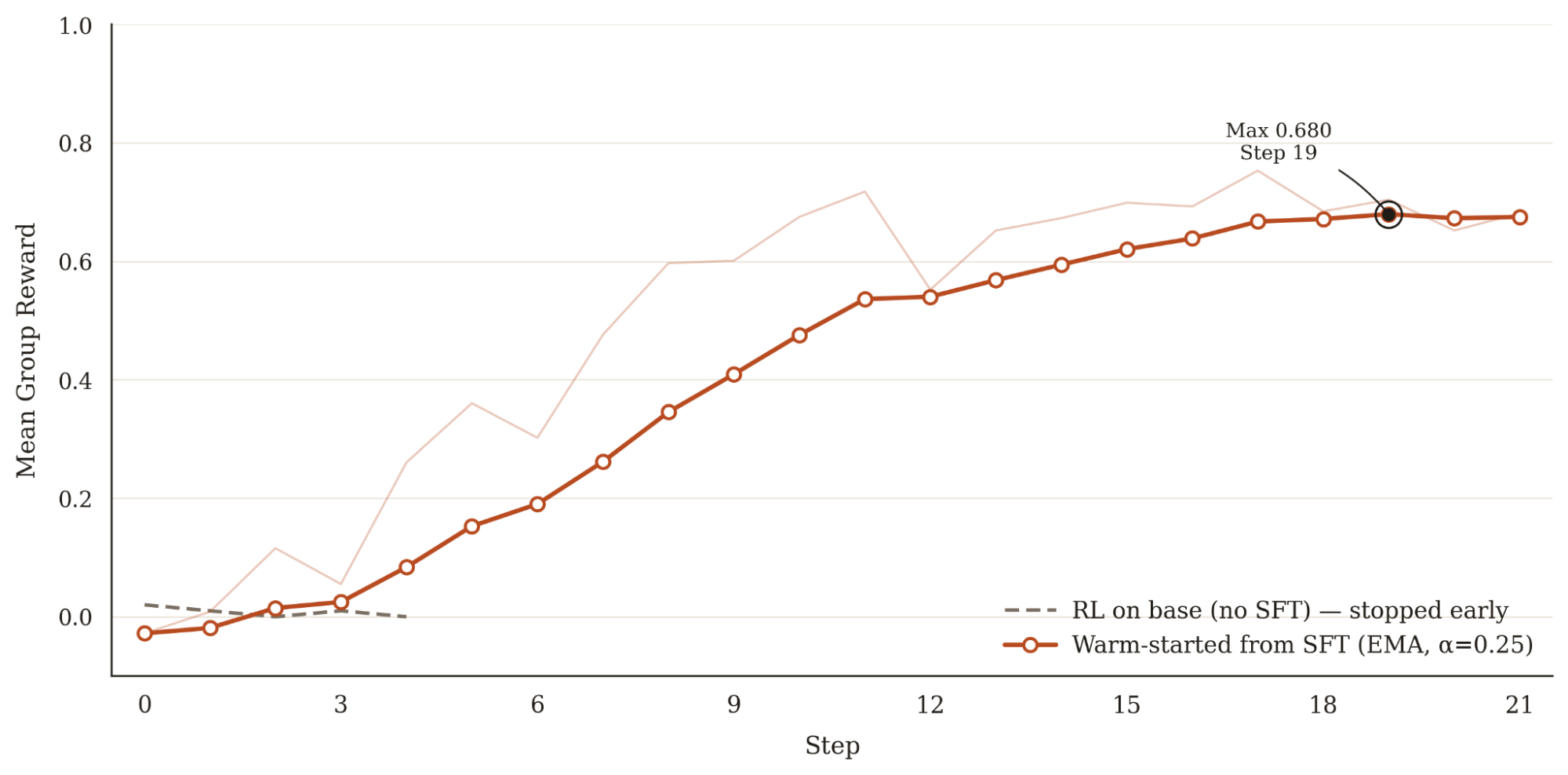
Reinforcement Learning (RL). Our reinforcement learning recipe uses GRPO with VLM-as-a-judge reward. We score every trajectory with a per-task structured rubric: a hand-authored checklist of 2-5 criteria totaling to 1.0. It's graded from a single screenshot of the final canvas by Gemini 3.0 Flash, which returns per-criterion scores as JSON. We train on synthetic tasks generated by frontier models that conform to the shape and distribution of PhotopeaBench's own task types, while ensuring training and evaluation are close but disjoint. We find that the SFT step is criticalto get the model to respond to RL. Without it, the base model's pass@K is so low that all rollouts fail the tasks and there is no reward signal to update the model.
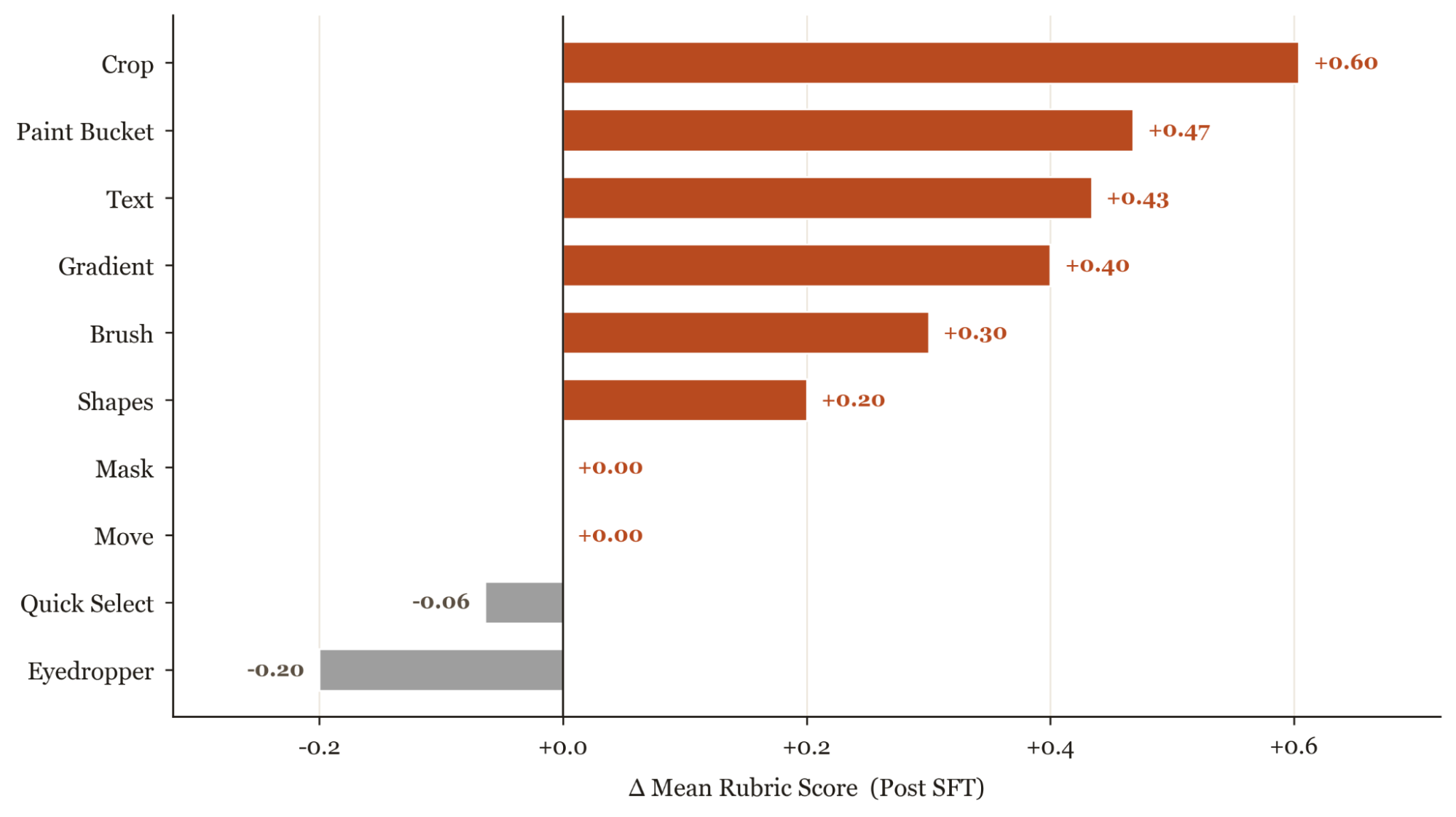
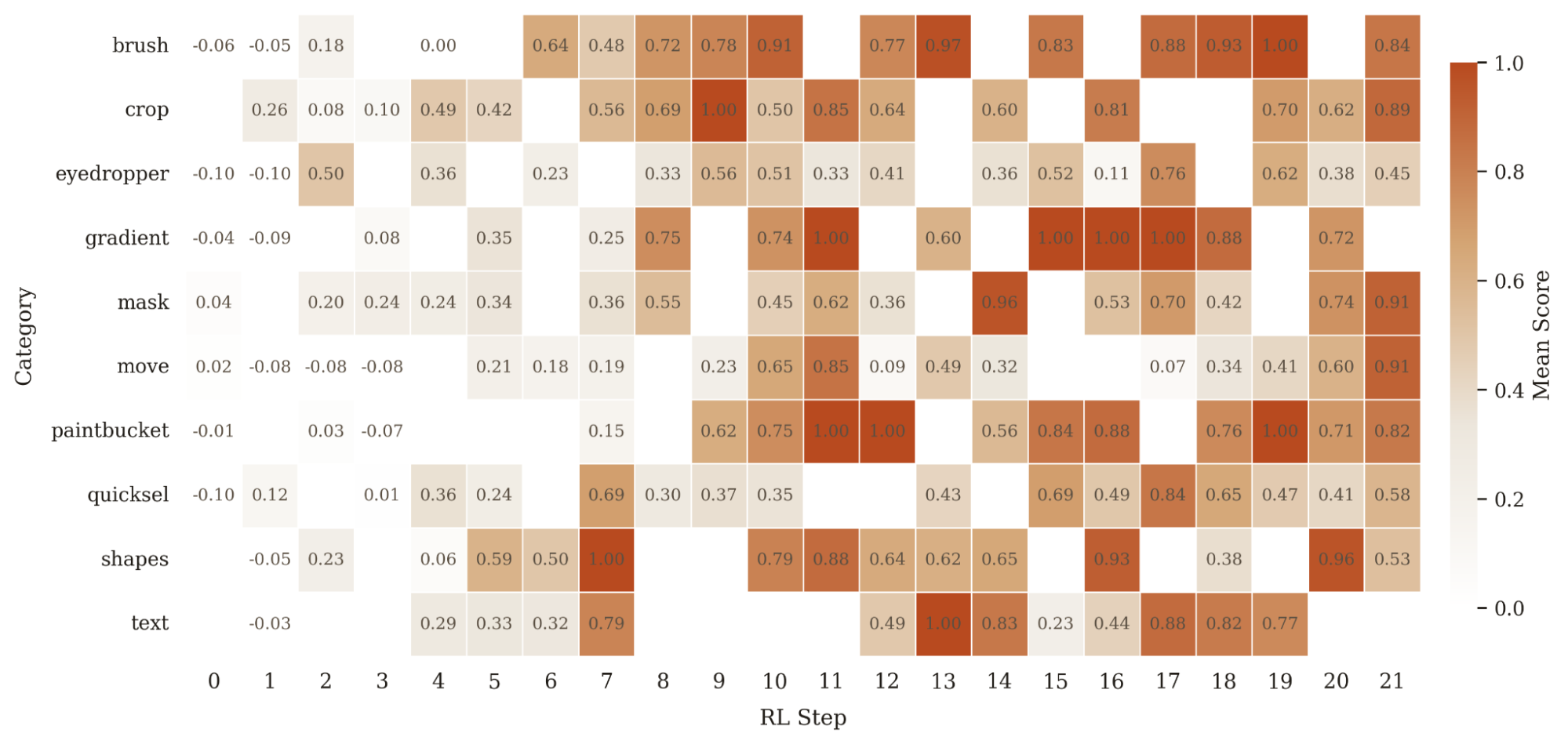
Looking per-category tells us where the gains come from. RL helps most where SFT was close-but-inconsistent (brush, gradient, shapes, mask) or had regressed below the base model (eyedropper, quicksel), and adds little where SFT had already saturated the task (paintbucket, crop). Text is the one outlier, since from manual trajectory inspection the bottleneck isn't typing, it's complex UI sub-skills like navigating Photopea's font dropdown and coordinating multi-color, multi-layer compositions. Even so, it is good to validate that every category's training reward climbs above its step-0 baseline, so RL is moving the policy in the right direction across the board.
Before we did the full RL run, we did several smaller bootstrapping runs whose purpose was not to train a usable model but to stress test the reward signal and the harness. The most consequential finding was that our original rubric was too coarse: a sum of a few binary indicators based solely on the final output screenshot did not provide enough signal for most trajectories. We revised the rubric to have more granular scoring and give the model credit for intermediate progress, which tripled the reward variance within groups and allowed the model to start hill-climbing.
The same runs also surfaced recurring failure modes that we fixed at the harness level rather than the policy: wasting turns trying to click instead of using efficient keyboard shortcuts, burning turns opening a new tab which destroys the trajectory, and reward-hacking by injecting Javascript into the page. In each case, we updated the prompt to more strongly guide the model in-context on preferred and efficient actions, which fed back into SFT data generation.
The other thing that made rubric and prompt iteration tractable was an internal tool we built called the observatory: a small web app that lets us scrub through every rollout and see the screenshot sequence alongside the assistant's thinking and tool calls, and inspect the grader's per-criterion breakdown on the final canvas.
Benchmarks
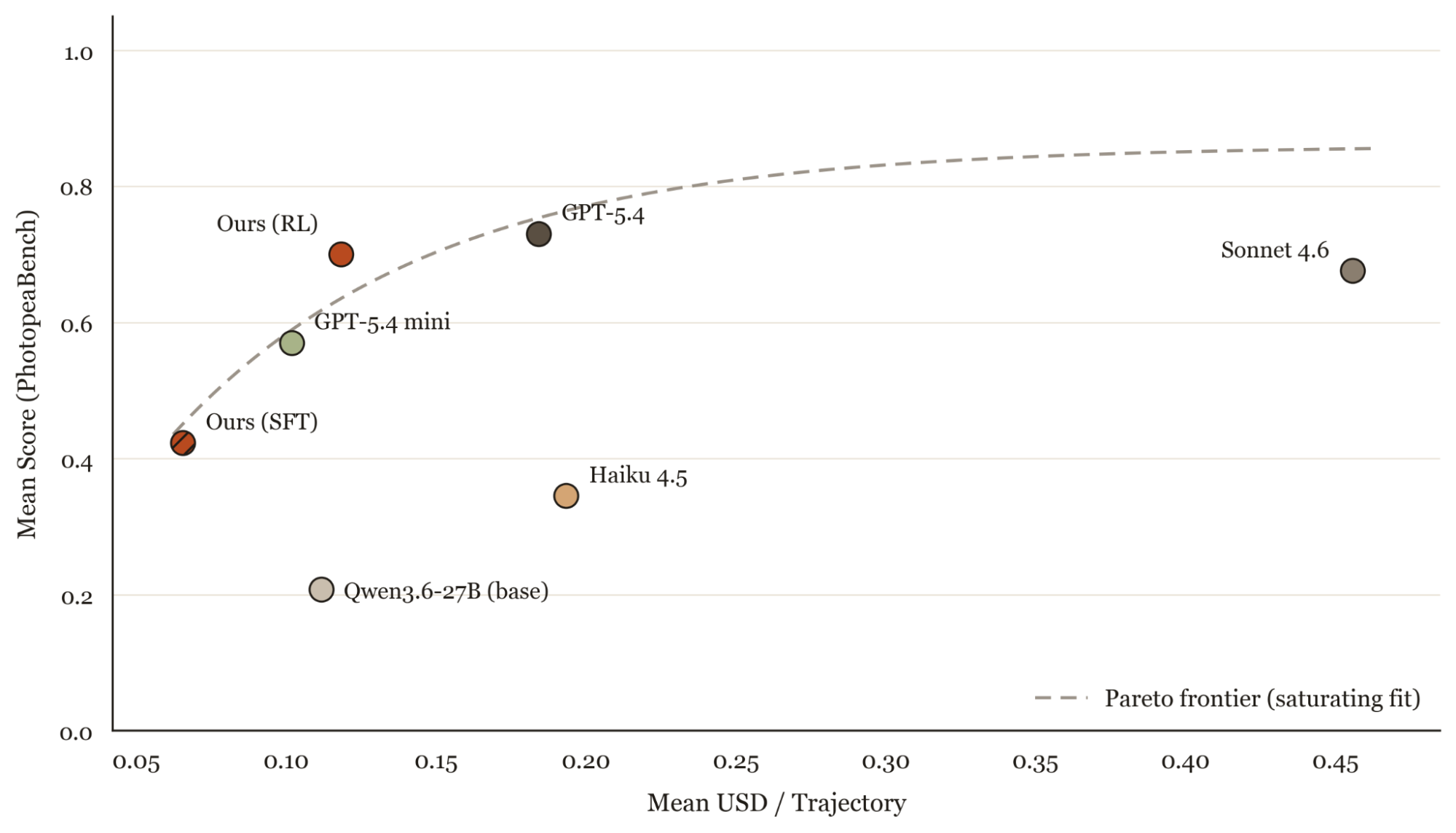
We evaluated the SFT+RL checkpoint against the same frontier baselines from Figure 3, this time scoring each model on both reward and per-trajectory cost. Our model lands on the Pareto frontier: above GPT-5.4 mini in reward at a comparable price, within a few points of GPT-5.4 at two-thirds the cost, and about 4x cheaper than Sonnet 4.6 for nearly the same reward.
The cost was computed by combining each trajectory's per-turn token usage with each provider's published rates. For the Qwen-27B checkpoints, we use Alibaba's OpenRouter inference rate as a benchmark, and assume the same cache-read/cache-write rate we observed for the Anthropic models on this eval apply on top.
Conclusion
SFT on filtered teacher trajectories, followed by GRPO with rubric reward, lands Qwen 3.6 27B on the Pareto frontier of PhotopeaBench. It matches Sonnet 4.6 in reward at a quarter of the cost, and falls within a few points of GPT-5.4 at two thirds the cost.
This work suggests the same recipe can carry over to any narrow domain where a frontier model can produce the training trajectories and a rubric can grade rollouts cheaply.
Future Work: Our iteration loop was bottlenecked by GPU compute and by the latency and cost of the Tinker API for RL runs. A few directions look promising once we escape that constraint.
- Async RL. Early in RL, a meaningful fraction of trajectories enter loops that are guaranteed to score zero. The model clicks the same dead UI element repeatedly, or opens a fresh tab and loses the canvas. Our setup is not fully async, so the slowest trajectory in a batch gates the whole step. The next thing to try would be async RL a la Pipeline RL.
- Denser reward signals. Per-step or per-tool-call rewards would credit intermediate progress more densely than the single end-of-trajectory rubric we use today. This should help most on long-horizon composition.
- Feedback descent.Our reward function currently collapses the grader's analysis into a single scalar, but Gemini 3.0 Flash is already producing a detailed natural-language description of where each trajectory went wrong and how it could be fixed. Recent work on feedback descent shows that this kind of verbal critique can serve directly as the optimization signal rather than being reduced to a number.